
一般聊到如何做数据分析的文章,都会从各个视角去介绍数据分析的思路和流程。但今天这篇文章,不会告诉你怎么按1234的步骤做数据分析,而是告诉你在数据分析中,不要做什么。正如查理芒格所言:“在生活和事业中,很多成功都来自于你避免了某些事情:比如早逝、糟糕的婚姻等。” 我相信,和“要做到好而深入的数据分析”相比,“不在数据分析中踩坑”会是更易于执行的事情,这是也这篇文章的诞生原因。
以下的错误集合,都是从身边的真实案例总结而来的。从错误出发,也会给出我们认为正确的做法和思路,希望能对大家的真实工作场景有所启发。
错误1:最后一刻才想起要数据分析
典型的场景是,领导和你说:明天交一个总结ppt给我。这时候你才想起来去提数和分析,很可能为时已晚。如果是常规的数据可以看内部的数据平台去获取;但如果是个性化的看数需求,就必须经历以下这些步骤:确定埋点方案、开发埋点、与数据分析师的具体提数需求沟通、实际提数、整理数据、最终分析。在这么长的链路中,如果有哪一步漏了,都有可能导致你拿不到想要的数据。
解法:从项目初始阶段便需要有数据思维
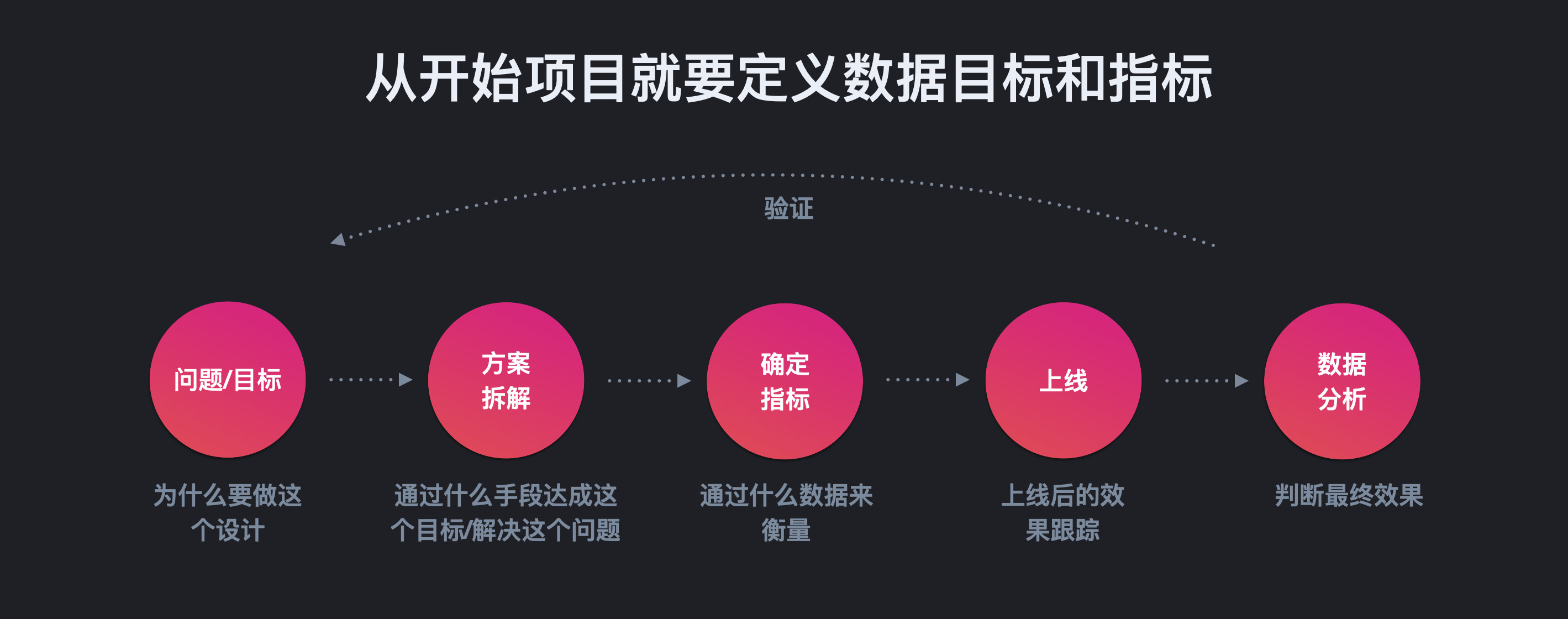
正确的方式是怎样的呢?应该是从项目开始,就根据你的方案,去定义你应该看什么数据来衡量最终的设计成败。这样一来的好处是,首先会倒逼我们从考虑方案的时候,就专注于能带来实际数据提升的方案,避免自嗨型方案、没有办法衡量结果成败的方案;其次是这样才能保证,我们在埋点的时候不会漏掉本该埋的数据,避免最终上线出现没有埋数据,导致无法衡量结果的情况。
错误2:对基础数据指标的定义不了解
不了解基本的数据指标概念,也是一个常犯的错误。例如说我们常遇到团队中的新人会有这样的疑问:客单价和 UV 价值有什么差别?UV 点击率和曝光点击率有什么差别?这就是对于数据指标的基本概念理解不足造成的。如果连指标都的含义都没有了解清晰,对于进一步的数据分析一头雾水也是难免的。
解法:从定义来初步认识,从影响因素和场景来加深理解
首先,最简单粗暴的方式,就是通读指标解释。一般数据平台都有地方专门解释这个指标的背后公式,这些解释会帮助我们建立对不同指标的初步理解。
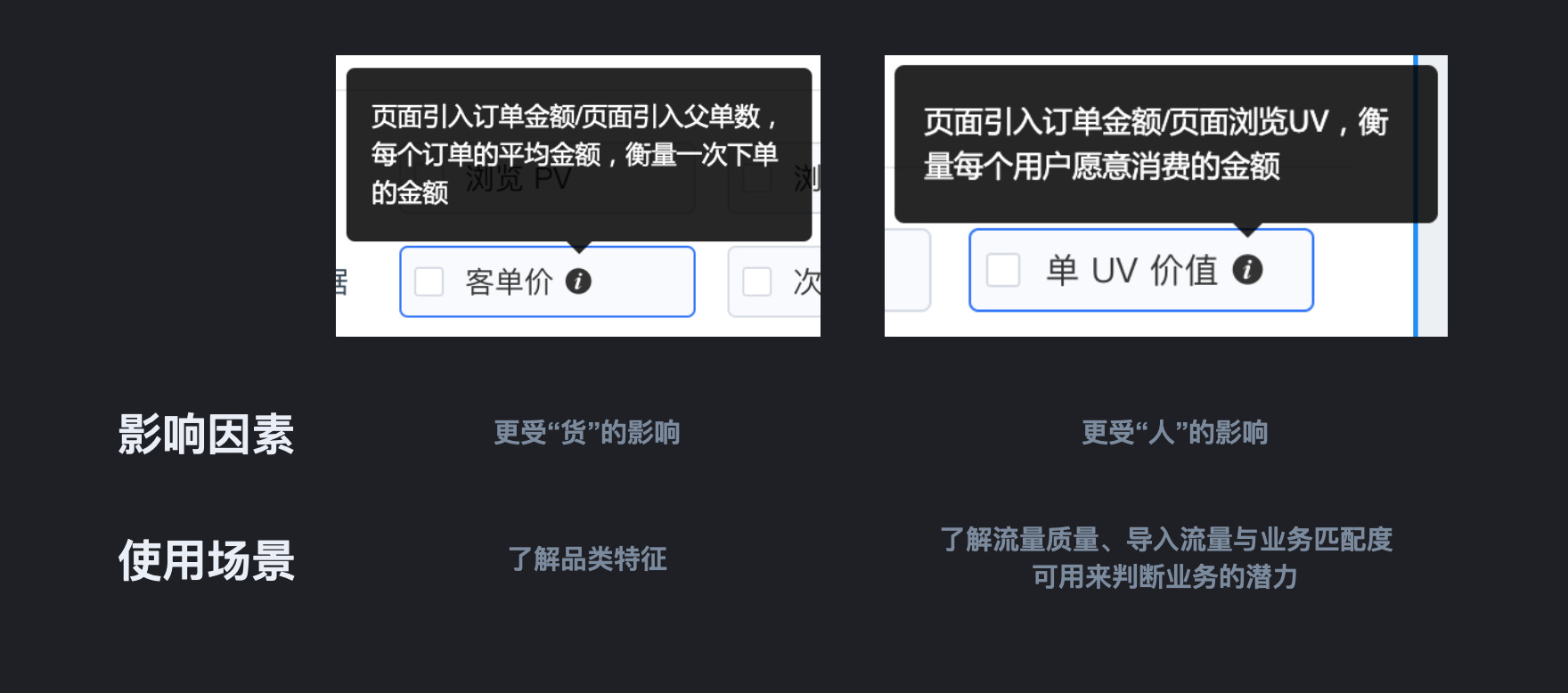
更进一步,有两个角度可以尝试去思考。例如以客单价和单 UV 价值的案例来说,第一个角度,是看这个指标的关键影响因素。像客单价,是更容易受到货的属性影响的,奢侈品的客单价天然就会趋向于比消费品的客单价更高;单 UV 价值,更容易受到流量质量的影响,比如把促销敏感型的用户导入了奢侈品的频道,这个时候,一般 UV 价值是会极低的,而客单价可能没有太大的变化。第二个角度是看这个数据指标的使用场景。如客单价,可以用来看这个业务的品类特征如何,UV 价值,是用来看流量与业务匹配度,以及判断业务的潜力。比如,看要不要给到这个业务更多的资源,就可以看 UV 价值,因为 UV 价值高,就代表了给这个地方更多的同类流量,它的 GMV 就会更高。
错误3:分析逻辑链缺失
一个典型的案例,是只看了 GMV 上涨,就下定论说代表我的策略是成功的。为什么有问题呢?因为 GMV 上涨是各种变量综合导致的结果,如果不去深入分析其中到底是什么变量导致了 GMV 上涨,是不能直接跳过中间的逻辑链去下判断的。
解法:拆公式、拆链路

首先是从公式上直接开始分析。假设你之前的策略是提升转化率——那么在如上图的公式拆解中,虽然最终的gmv是提升的,但因为gmv提升主要是由浏览UV的提升带来的,因此转化率相关的策略可以说是失败了。

第二个思路,是由宏观到微观的方式去排查问题的方式。电商场景中,我们可以先看交易数据,看下是否达到了当初的预期,与历史对比是涨还是跌;然后再看流量数据,因为流量是影响 gmv的最大因素之一,这时候就可以分析交易数据的涨跌,是否是因流量的涨跌导致的;或者说是流量质量导致的转化率低等等;如果分析完,发现流量的影响不大,这时候可以进入下一级,去分析核心的节点是否存在问题。比如在电商黄金流程场景中,我们看搜索、商详、加购等核心页面的漏斗;而在大促场景中,我们可能会去看主会场的主推楼层们是否达成了预期的产出。这个就是以宏观到微观去排查问题的思路。
错误4:只抓了一条变量,忽略其他关键变量
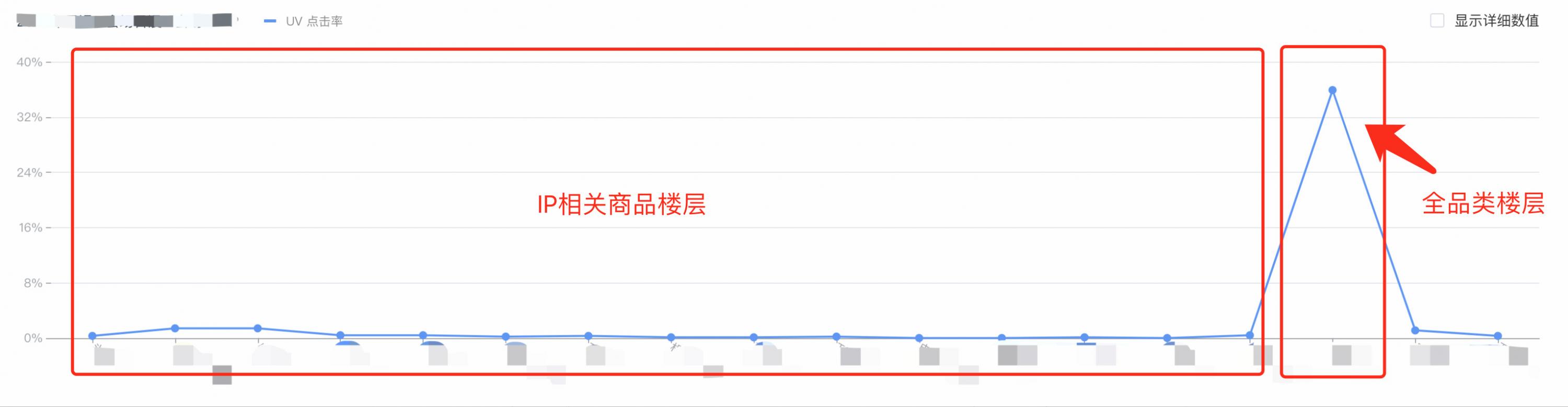
有时候,我们的分析看起来有理有据、是有数据支撑的,初步看起来逻辑没有大问题。例如说,根据以下这个点击率的图表,似乎可以直接推测出这个页面里,除了XX楼层以外,其他的楼层表现不佳。于是我们可以直接下结论说:未来还做这样的页面的时候,迭代的方向,就是直接把表现不佳的楼层去掉,只留下这个表现好的楼层了吗?——这样的结论是失之轻率的。那到底问题出在哪里呢?
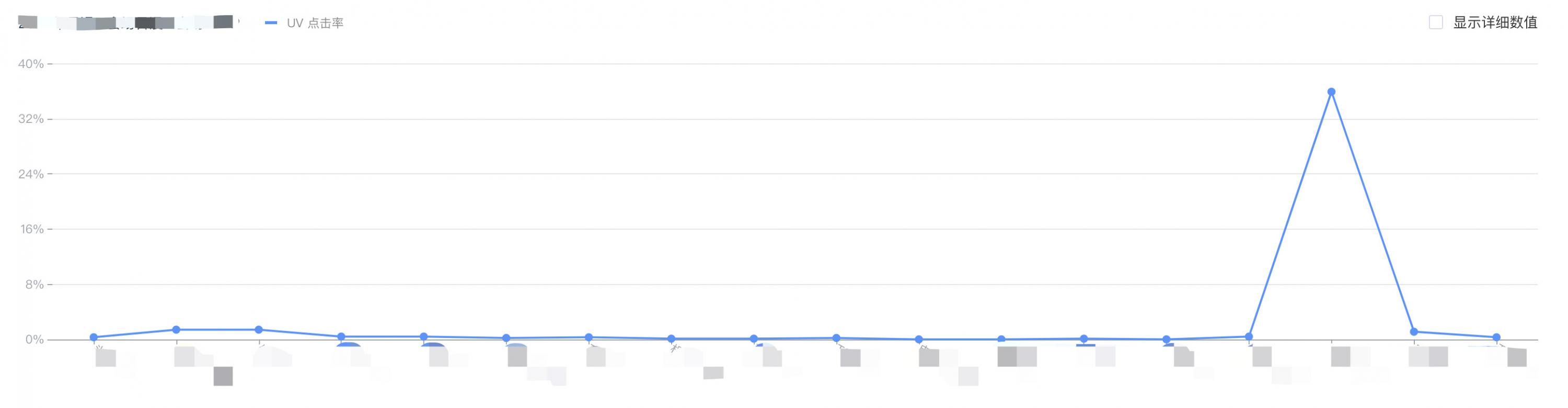
问题在于:我们似乎建立了一个前提,即这样的数据结论是仅仅源自“楼层的定位或者设计”这一个变量而导致的。因此数据好=楼层的定位和设计成功,要延续;数据差=楼层的定位和设计成功,要复用。但是现实情况,永远比我们设想的要复杂。仅抓了一条变量就贸然下结论,风险是比较大的。
解法:找到各种关键变量,排除或确认这个变量的影响
回到真实业务场景,会发现还有更多变量。在这个案例中,我们第二个要考虑的变量,是流量渠道。以上图表是APP的楼层数据,那么M端是否是一样的趋势呢?拉出来M端的点击率图表一看,会发现趋势完全是不一致的:
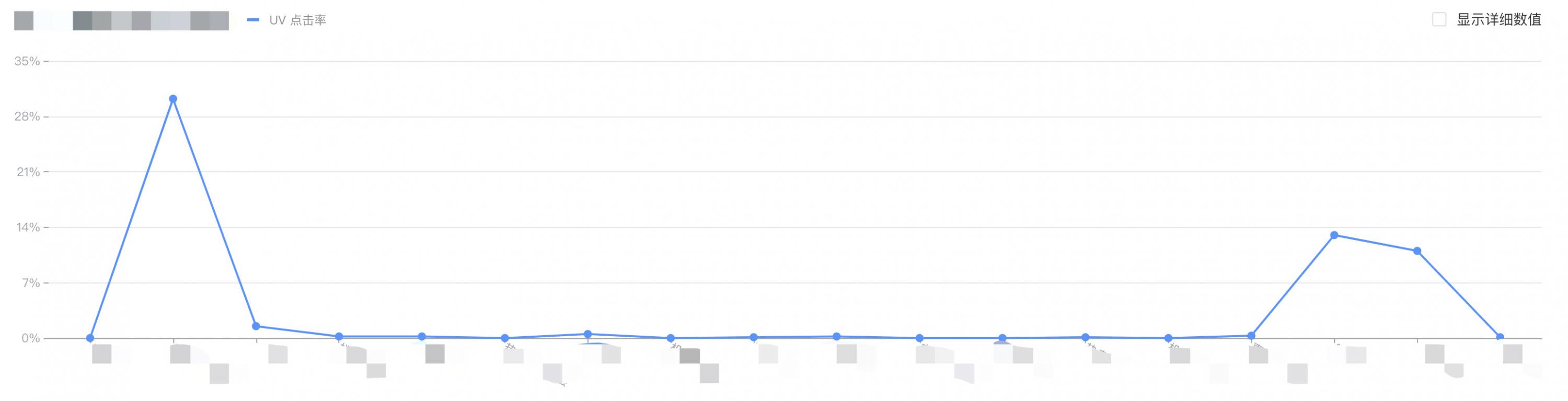
此时有了第一个猜测:APP端流量更多内部自流量,M端更多外推流量,因此我们可以得出,这个点击率反映的是JD自有流量和外推流量对于这个页面完全不同的行为特征。
那为什么外推带来的用户和站内的用户,对同一个页面的需求差异那么大呢?因为这是一个以 IP 内容为主的页面,页面大部分区域都是 IP类商品,是带有一定粉丝向的。直到页面很下方才有非 IP 角度的商品,这里的商品是全品类的。说到这里,大家应该意识到了:这里还有第三个变量——楼层的内容差异。此时把第二个变量与第三个变量交叉判断,就是本次数据分析的关键问题:楼层内容与流量渠道的匹配度高低。
根据上面的分析,我们可以得出最终的结论:
- ① 外推带来的用户,对于页面的主推 IP 内容更感兴趣,说明本次外推触达的用户是更精准符合这个页面的用户群体;
- ② 而站内的用户,对于页面的主推内容是缺乏兴趣的,只有看到全品类楼层才有兴趣,说明站内自有流量与本次 IP 页面不太匹配;
- ③ 综上,在后续进行同类的 IP 页面的运营活动时,若想要达成更精准的人货匹配,建议把流量重点放在外推的流量上,而降低对站内流量的效果的预期。
以上就是一次如何排除各自变量影响的分析案例。基本的思路是:不要满足于你手上抓住的那条变量,而是尽可能多地找到这个场景里的关键变量,再一个个变量去排除或者确认它的影响,最终才得到较合理的结论。
小结:跨过分析门槛→深挖分析深度
总结以上的问题,发现这些问题本质上是从分析小白→到分析进阶者之间遇到的一些门槛。就如下图一样,要输出一份符合逻辑、能对业务有实际帮助的数据分析,我们就需要避免踩到这些坑。

而我们的解法,就只有踏实做好以下的事情:
- 1.在全链路有数据意识,避免在最后一步才想起要数据分析;
- 2.对数据指标有基本认识,避免拿着指标不一头雾水;
- 3.分析时要有溯源逻辑,避免仅通过一个指标判断成败;
- 4.穷举各种可能的变量,避免只抓到一个变量就下判断。
原文地址:京东设计中心JDC(公众号)
作者:刘欢







评论0